
What’s there to C?
First things first
The behavior of the program with and without optimization.
The code shown below is the code that we looked at in the blog about the signal () function and the kill command/system call.
#include
#include
#include <sys/types.h>
#include
int *i_ptr;
int sh_val = 0;
void sig_handler (int sig)
{
sh_val++;
printf (“sig_handler: sh_val = %d\n”, sh_val);
}
int main (int ac, char *av[])
{
i_ptr = &sh_val;
signal (SIGUSR1, sig_handler);
printf (“main: pid is %u\n”, getpid ());
while (1) {
if (*i_ptr > 0) {
printf (“main: SIGUSR1 received. Quitting\n”);
break;
}
}
return 0;
}
$ ./signal
main: pid is 75554
sig_handler: sh_val = 1
main: SIGUSR1 received. Quitting
$
$ kill -SIGUSR1 75554
$
The behavior of the program, after we compile using the -O2 option to turn on optimization is as shown below:
$ gcc -02 volatile.c -o voldemo
$./voldemo
main: pid is 2159
sig_handler: sh_val = 1
sig_handler: sh_val = 2
sig_handler: sh_val = 3
Terminated
$
$
$ kill -SIGUSR1 2159
$ kill -SIGUSR1 2159
$ kill -SIGUSR1 2159
$ kill -SIGTERM 2159
$
Note the program execution didn’t terminate even after sending the SIGUSR1 signal thrice to the program using the kill command. We can see that our signal handler function was called by the operating system as expected, but the infinite loop didn’t terminate even though the value of sh_val did get incremented thrice.
Finally, we used a different signal, the SIGTERM, to end our program execution. We could have terminated the program by sending some other signal also, or by pressing the Ctrl-C key combination from the keyboard on the terminal in which the program was executing.
Let us take a look at the generated assembly code to try and understand what caused the difference in behavior when the code was optimized.
Comparison of assembly code generated with and without optimization
Let us look at the X86 assembly output of the program under discussion. The C version of the program is below:
The most relevant part of the code (in the context of optimization), is the infinite loop in the main () function. And that snipper is shown below:
while (1) {
if (*i_ptr > 0) {
printf (“main: SIGUSR1 received. Quitting\n”);
break;
}
}
Assuming the program was saved as volatile.c, the X86_64 assembly code for this program can be generated by the command gcc -S volatile.c
With no optimisation specified, the assembly code generated by the compiler for this loop is below
X86_64 Assembly code without optimization
.
.
call printf
.L5:
movq i_ptr(%rip), %rax
movl (%rax), %eax
testl %eax, %eax
jle .L5
movl $.LC2, %edi
.
.
X86_64 Assembly code with optimization
.
.
call printf
movq i_ptr(%rip), %rax
movl (%rax), %eax
.L4:
testl %eax, %eax
jle .L4
movl $.LC2, %edi
.
.
The two pieces of assembly code look different, even if the statements are pretty much similar. There is one change, involving two statements, that has a major impact on the program behavior. These are two statements that do the following.
1) The movq statement loads the rax register with the 8-byte address that is there in the pointer i_ptr (address of sh_val)
2) The movl statement loads the eax register with the integer value that is present in the address that has been loaded into the rax register.
In the optimised version generated by the compiler, these two assembly statements got moved from inside the loop to just before the loop. This means that the value of the sh_val variable is loaded once into the eax register and never updated again in the loop. The result of this is that, in the optimized version, even if the value of the sh_val variable gets changed by the sig_handler () function getting called by the OS, it does not affect the code inside the loop. The code in the loop will just continue to use whatever value was loaded into the eax register before the loop started
I guess, by now it is pretty obvious why the compiler did this. As far as the compiler is concerned, the value of the value of sh_val (*i_ptr) is not getting changed inside the loop, at all. And memory accesses to read values from the memory are pretty expensive compared to instructions that just involve CPU registers (and there are two memory accesses in this case). So if the variable is not changing inside the loop, why read it multiple times?
So now we know that optimization messed with the program’s behavior. But we do need optimization and when dealing with hardware, we are sure to have code like the infinite loop of the code shown. And that is where the volatile type qualifier comes into play.
Once again the type qualifier volatile
If we modify the same program with the type qualifier used when declaring the pointer variable, even with optimization, the program behavior will be as before (without optimization):
#include <stdio.h>
#include <signal.h>
.
.
volatile int *i_ptr;
int sh_val = 0;
void sig_handler (int sig)
{
sh_val++;
printf (“sig_handler: sh_val = %d\n”, sh_val);
}
int main (int ac, char *av[])
{
.
.
return 0;
}
The behavior of the program with the volatile type qualifier, compiled with optimization is shown below:
$ gcc -02 volatile.c -o voldemo
$./voldemo
main: pid is 2535
sig_handler: sh_val = 1
main: SIGUSR1 received. Quitting
$
$ kill -SIGUSR1 2535
$
A look at the assembly code generated after we used the volatile type qualifier with *i_ptr and compiled with optimisation turned on will show the effect of the type qualifier on the generated assembly code:
Optimised Assembly code with volatile specified:
.
.
call printf
movq i_ptr(%rip), %rdx
.L4:
movl (%rdx), %eax
testl %eax, %eax
jle .L4
.
.
This looks very similar to the code generated without any optimisation. Still there is one optimisation being done – the 8 byte address in the i_ptr pointer variable is now moved into the rdx register and this is being done outside the loop.
But the 4 byte value from the location specified by the address in the rdx register is moved every time the loop is executed. This means that whenever the signal SIGUSR1 is received by the program (and the operating system calls the sig_handler ()function, resulting in the incrementing of value of sh_val), the loop will end because the testl instruction will find that the Zero Float is no longer set (an explanation of the relevant assembly statements is given below).
An explanation of the assembly code that we were looking at.
X86_64 Assembly code without optimisation
.
.
call printf
.L5:
movq i_ptr(%rip), %rax
movl (%rax), %eax
testl %eax, %eax
jle .L5
movl $.LC2, %edi
.
.
Let us take a look at each of the lines beginning with the start of the loop (.L5:) upto the end of the loop (jle .L5) of the unoptimised code.
.L5:
This just creates a label that can be used as an address to branch to.
moveq i_ptr(%rip), %rax
Move the 8 byte address that is stored in the pointer i_ptr (address of sh_val) into the rax register
movel (%rax), %eax
Move the 4 byte data from the address stored in the rax register into the eax register
testl %eax, %eax
Does a bitwise and of the 4 byte value in the eax with itself. This instruction can be done on two 4 byte registers or one 4 byte register and a 4 byte immediate value. This will set the Zero Flag and Sign Flag.
jle .L5
If the Zero Flag (or Sign Flag) is set, jump to the given address (in our case .L5), thus creating a loop that will execute as long as the value in sh_val doesn’t become greater than 0.
So, any time the signal SIGUSR1 is sent to the program (either using the mkill program or the kill command) the sig_handler () function will be called by the operating system and the value of sh_val gets incremented from 0. So the testl instruction will result in the ZF becoming 0 and thus ending the loop.
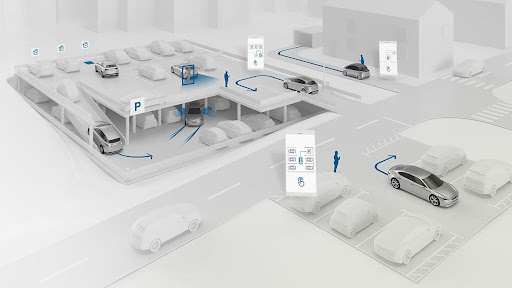
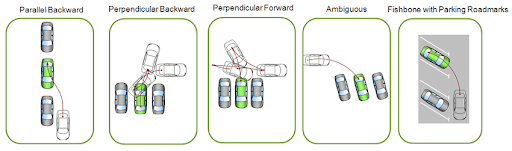
- Risk-Based Testing: Identifying critical parking scenarios, such as navigating through busy parking lots or avoiding collisions with pedestrians, allows developers to prioritize testing efforts effectively. Probability and impact analyses further guide decision-making, ensuring that resources are allocated to test high-risk situations comprehensively, thus minimizing potential safety hazards related to parking.
- Equivalence Partitioning: Equivalence partitioning facilitates systematic testing of parking-related functionalities by dividing the input space into distinct classes. Testing scenarios at the boundaries of input ranges ensure that the AV system behaves reliably under various parking conditions, such as different parking space dimensions or environmental factors.
- Combinatorial Testing: Combinatorial testing techniques like pairwise testing enable efficient coverage of input parameter combinations relevant to parking scenarios. By testing different combinations of parking space dimensions, vehicle speeds, and environmental conditions, developers ensure that the AV system’s performance remains robust across a wide range of parking situations.

Image depicting a high-risk parking scenario, such as navigating through a crowded parking lot with pedestrians and obstacles.
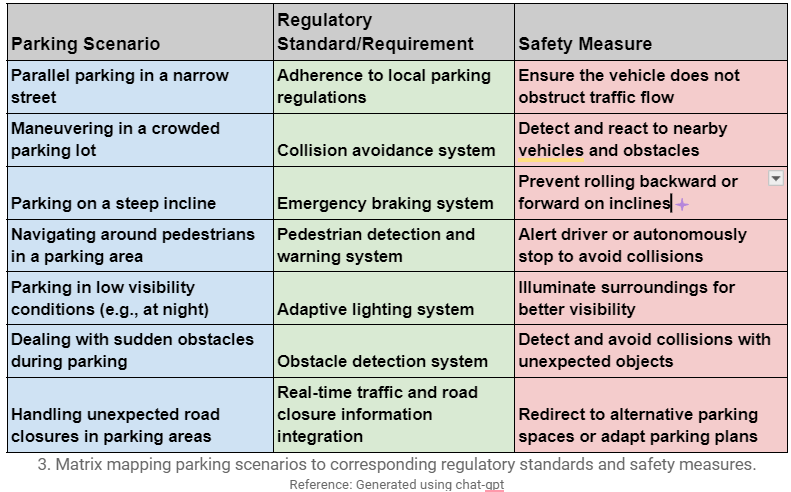
- Requirements Traceability: For AVs, meeting specified functional and safety requirements is imperative, especially concerning parking maneuvers. By mapping parking scenarios to specific requirements related to obstacle detection, collision avoidance, and adherence to parking regulations, developers ensure that every aspect of the AV system’s functionality is thoroughly tested and validated.
If you’re eager to explore the exciting frontiers of Automotive Cybersecurity and Functional Safety in Automotive and more about our groundbreaking initiatives in ADAS, reach out to us!
Author




 Embedded Software
Embedded Software Digital Twins & Simulation
Digital Twins & Simulation Software-Driven Verification (PSS)
Software-Driven Verification (PSS) Connectivity & Protocols
Connectivity & Protocols Functional Safety & Cybersecurity
Functional Safety & Cybersecurity ADAS & Autonomous Vehicle V&V
ADAS & Autonomous Vehicle V&V GenAI/LLM
GenAI/LLM