
Abstract:
Introduction:
- Initialize a source frame with synthetic pixel data (e.g., RGBA pattern)
- Scale it to a target resolution using any scaling algorithm (e.g., nearest neighbour, bilinear, bicubic) in C
- Copy the scaled frame to a simulated output memory
- Repeat the operation 100 times to emulate a video stream
- The raw scaling capability of ARM CPUs
- The system’s ability to maintain a target frame rate (e.g., 60 FPS or better)
- How memory bandwidth and CPU load affect consistent scaling
Simple User Space C Code
1. Basic Memory Read and Write
The first step in evaluating CPU-based performance for image and video processing was to establish a simple baseline by measuring the time taken for repeated memory read and write operations. This served as a foundational test, helping to understand how efficiently the CPU can move raw frame data in memory, without any image processing overhead. For this purpose, a straightforward C program was written that allocates a single 1920×1080 resolution frame in memory, fills it with random pixel values, and then repeatedly copies this frame data into another allocated buffer.
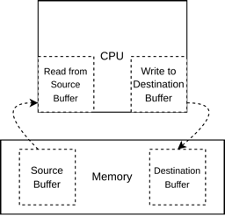
To simulate video-like behavior, the copy operation was performed a hundred times, mimicking 100 frames being read and written during a typical playback scenario. The copying process used the standard memcpy() function, which provides a fast and reliable way to benchmark raw memory bandwidth. OpenMP was employed to parallelize the loop executing the copy operation across multiple threads — in this case, four — to test how well the system scales with parallel memory tasks. The use of `omp_get_wtime() allowed precise timing of the entire loop, giving insight into total operation latency.
This baseline setup revealed key characteristics of the system’s memory performance. Since no processing was done on the image data, the test isolated the cost of memory I/O alone. It helped understand how well the CPU handles frame-sized memory blocks under repeated access and gave an initial idea of what portion of frame processing time might be consumed purely by memory movement, independent of any image manipulation like scaling or filtering. This experiment served as the groundwork before progressing to more complex operations like CPU-based scaling.
2. Scaling Operation – Basic Mechanism – Nearest Neighbour Algorithm
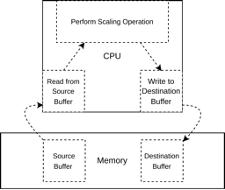
Mathematical Formulation:

Implementation in C
void scaleResolution(Resolution* src, Resolution* dst) {
float x_ratio = (float)src->width / dst->width;
float y_ratio = (float)src->height / dst->height;
#pragma omp parallel for collapse(2)
for (int y = 0; y < dst->height; y++) {
for (int x = 0; x < dst->width; x++) {
int srcX = (int)(x * x_ratio);
int srcY = (int)(y * y_ratio);
int srcIndex = (srcY * src->width + srcX) * PIXEL_SIZE;
int dstIndex = (y * dst->width + x) * PIXEL_SIZE;
memcpy(&dst->data[dstIndex], &src->data[srcIndex], PIXEL_SIZE);
}
}
}
Experimentation Result:
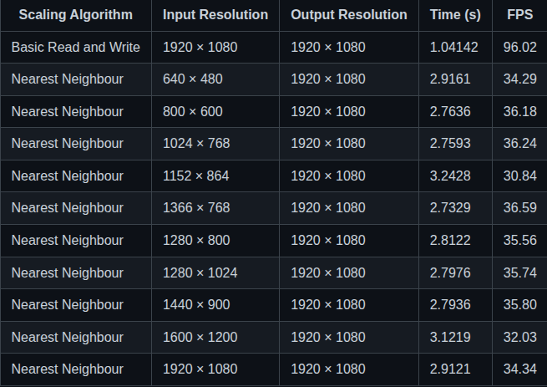
Performance of Nearest Neighbour Algorithm on Raspberry Pi 3:
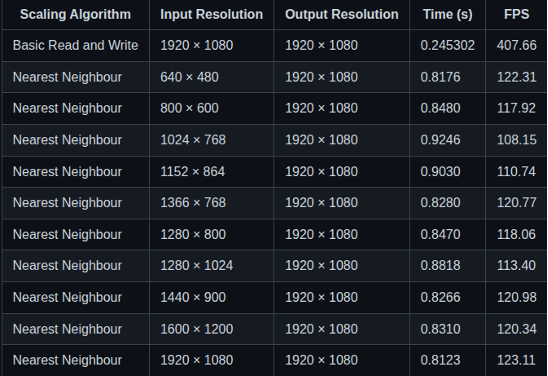
Performance of Nearest Neighbour Algorithm on i.MX 8M Mini:
Key Observations:
- Across all input resolutions, the i.MX 8M Mini consistently delivers much faster processing times and higher frame rates (FPS) than the Raspberry Pi 3
- Both devices were also tested on a no-scaling path. The i.MX 8M Mini still processes this faster than the Pi 3, confirming a more efficient memory read/write bandwidth or faster memory subsystem
2. Bilinear Interpolation
Mathematical Formulation:
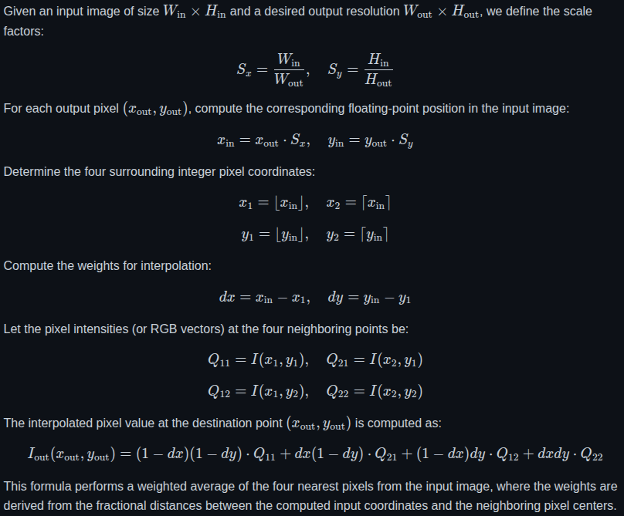
Implementation in C
float x_ratio = ((float)src->width – 1) / dst->width;
float y_ratio = ((float)src->height – 1) / dst->height;
#pragma omp parallel for collapse(2)
for (int y = 0; y < dst->height; y++) {
for (int x = 0; x < dst->width; x++) {
float srcX = x * x_ratio;
float srcY = y * y_ratio;
int xL = (int)srcX;
int yT = (int)srcY;
int xH = (xL + 1 < src->width) ? xL + 1 : xL;
int yB = (yT + 1 < src->height) ? yT + 1 : yT;
float xWeight = srcX – xL;
float yWeight = srcY – yT;
int indexTL = (yT * src->width + xL) * PIXEL_SIZE;
int indexTR = (yT * src->width + xH) * PIXEL_SIZE;
int indexBL = (yB * src->width + xL) * PIXEL_SIZE;
int indexBR = (yB * src->width + xH) * PIXEL_SIZE;
int dstIndex = (y * dst->width + x) * PIXEL_SIZE;
for (int c = 0; c < PIXEL_SIZE; c++) {
float top = src->data[indexTL + c] *
(1 – xWeight) + src->data[indexTR + c] * xWeight;
float bottom = src->data[indexBL + c] *
(1 – xWeight) + src->data[indexBR + c] * xWeight;
dst->data[dstIndex + c] = (unsigned char)(top * (1 – yWeight) + bottom * yWeight);
}
}
}
}
Experimentation Result:
Performance of Bilinear Interpolation on Raspberry Pi 3:

Performance of Bilinear Interpolation on i.MX 8M Mini:

Key Observations:
- On average, the i.MX 8M Mini achieves ~2.9× higher FPS than the Raspberry Pi 3
- Interestingly, processing time remains nearly constant across different input resolutions for both platforms



 Embedded Software
Embedded Software Digital Twins & Simulation
Digital Twins & Simulation Software-Driven Verification (PSS)
Software-Driven Verification (PSS) Connectivity & Protocols
Connectivity & Protocols Functional Safety & Cybersecurity
Functional Safety & Cybersecurity ADAS & Autonomous Vehicle V&V
ADAS & Autonomous Vehicle V&V GenAI/LLM
GenAI/LLM